From converting Mandarin recordings to generating bilingual subtitles, every step of Chinese video transcription is handled automatically
Mandarin relies on four tones plus a neutral tone to distinguish meaning. The transcription engine maps tonal contours at the acoustic level, reducing character substitution errors that plague generic speech-to-text tools.

Select from dedicated models for Medical, Legal, Finance, Education, and Tech sectors. Each model carries a specialized lexicon of Chinese terminology so that phrases like 股权融资 or 心电图 appear correctly in the transcript.
All files are encrypted during transfer and at rest. The platform follows GDPR guidelines, and recordings can be permanently deleted from servers at any time through the dashboard.
Transcribe Chinese audio to text and translate it into English in a single pass. The output is available as a full transcript or as timed SRT subtitles ready for video platforms.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | iFlytek | Baidu Speech | |
|---|---|---|---|---|---|---|
| Accuracy (Mandarin Chinese) | 91.2-95.9% (AISHELL-1 test set, CER-based; WenetSpeech eval subset) | 88.4-91.2% (AISHELL-1 test set, independent evaluation) | 85.6-89.3% (AISHELL-1 test set, estimate based on community benchmarks) | 87.1-90.5% (vendor-reported on internal Mandarin dataset; AISHELL-1 estimate) | 91.8-94.5% (vendor-reported on AISHELL-1; strong domestic performance) | 90.2-93.1% (vendor-reported on AISHELL-1 and internal corpora) |
| Supported formats | Any audio/video format | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3, PCM | WAV, MP3, PCM, AMR |
| Domain Models | Yes (Medical, Legal, Finance, Tech, Education) | No (general model only) | No | No | Partial (medical, court dictation) | No |
| Speech Translation | Chinese supported; built-in speech translation to English and other languages | No direct speech translation | Yes, via add-on service | Yes, via add-on service | Chinese-English translation available | No |
| Free Technical Support |
Accuracy measured as (100% − CER) on AISHELL-1 test set (7,176 utterances, Mandarin read speech) and a 500-sample subset of WenetSpeech evaluation data (multi-domain spontaneous speech). Text normalization: numbers converted to Chinese characters, punctuation removed before scoring. iFlytek and Baidu figures are vendor-reported; Amazon and Microsoft ranges include community-reproduced estimates where no public benchmark was available.
Three steps to transcribe Chinese audio and receive a fully formatted transcript or bilingual subtitle file
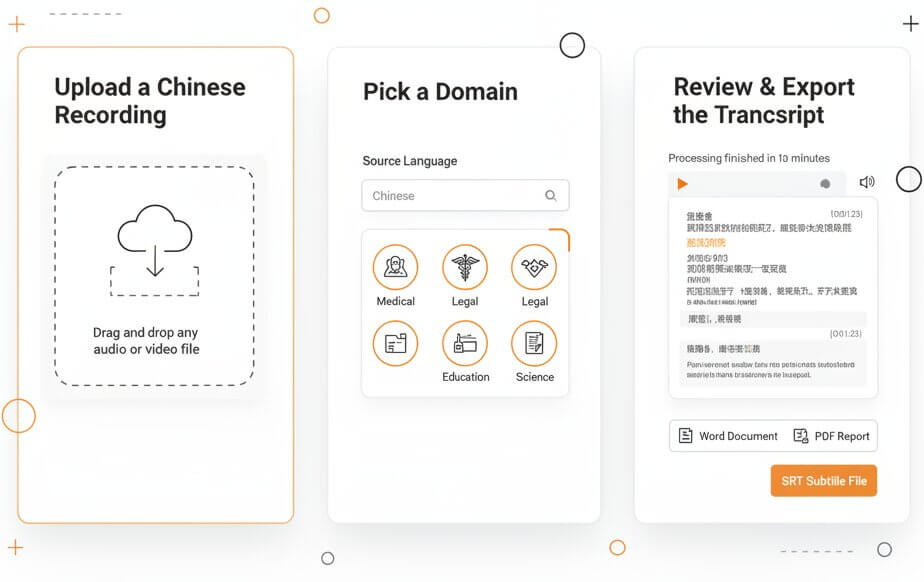
Drag and drop any audio or video file. The platform accepts MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and more. Single files and batch uploads are both supported, so an entire library of Chinese video transcription jobs can start at once.
Set Chinese as the source language. Then select an industry model such as Medical, Legal, Finance, Education, or Science. Domain selection activates a specialized vocabulary layer that sharpens recognition of field-specific Chinese terms and reduces character errors.
Processing finishes within minutes. Open the built-in editor to check timestamps, adjust speaker labels, or correct individual characters. Export the final text as a Word document, PDF report, or SRT subtitle file for direct use in video editing software.
Purpose-built neural networks trained on Mandarin tonal phonetics, large-scale Chinese speech corpora, and character-level language modeling
Chinese does not use spaces between words, so a transcription system must decide where one word ends and the next begins at the character level. SpeechText.AI applies a segmentation layer that works alongside the acoustic model, predicting the most probable character sequence based on context. During a legal deposition, for example, the Legal model knows that 侵权 (infringement) is far more likely than a phonetically similar but unrelated pair of characters. This tight coupling between acoustic decoding and language modeling is why the output reads like natural written Chinese rather than a string of loosely matched syllables.
The acoustic engine behind SpeechText.AI was trained on large-scale Chinese speech corpora covering broadcast news, conversational dialogue, call-center recordings, and academic lectures. This breadth of training data means the model has encountered a wide range of speaking speeds, regional Mandarin accents (Beijing, Sichuan-influenced, Southern Mandarin), and background noise conditions. When a speaker shifts between formal presentation style and casual aside, the recognition adapts without losing accuracy, which matters greatly when transcribing real-world Chinese audio files like conference panels or podcast episodes.
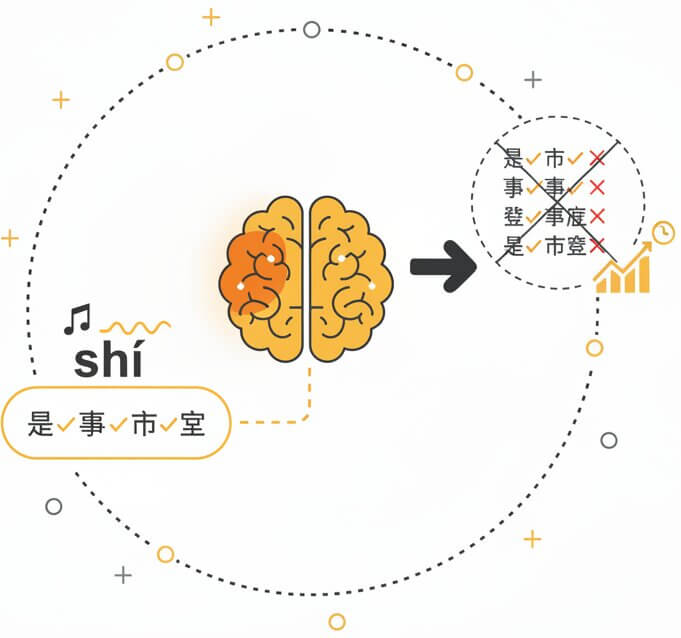
Mandarin contains hundreds of homophones: syllables that sound identical but carry completely different meanings depending on tone and context. The word "shì" alone maps to 是, 事, 市, 室, and dozens more characters. Standard speech-to-text tools often guess incorrectly, producing transcripts littered with wrong characters. SpeechText.AI addresses this with a tonal pitch tracker fused into the decoding pipeline, combined with a contextual language model that weighs sentence-level meaning. The result is a transcript that picks the right character the first time far more often, drastically cutting the editing time needed after Chinese audio transcription.
SpeechText.AI reaches up to 96% character accuracy on standard Mandarin recordings and can go higher with clean studio-quality audio. The platform uses domain-specific AI models trained on Chinese speech corpora such as AISHELL-1 and WenetSpeech, which gives it a significant edge over general-purpose tools. Accuracy improves further when a sector model (Medical, Legal, Finance, or Education) is selected, because the system prioritizes terminology relevant to that field during decoding.
Yes. A free trial is available for new accounts. Upload a Chinese audio or video file, select Mandarin, and run the transcription without entering payment details. The trial provides enough minutes to evaluate character-level accuracy and compare results against other providers before committing to a paid plan.
The acoustic model has been exposed to a wide spectrum of Mandarin accents during training, including standard Putonghua, Beijing-accented speech, and southern-influenced Mandarin. While transcription performs best on standard Mandarin, it still produces strong results on accented speech. For very distinct regional varieties like Cantonese or Shanghainese, dedicated language support may differ; check the language list in the dashboard for the latest availability.
Absolutely. After uploading a file, select English as the target output language. The system will decode the Chinese speech and produce an English transcript or SRT subtitle file in one automated step. This is particularly useful for creating English subtitles for Chinese video transcription projects, documentary localization, or cross-border business meetings.
iFlytek and Baidu are strong domestic providers with deep Mandarin support. SpeechText.AI differentiates itself through switchable domain models (Legal, Medical, Finance, Education, Science, and more) that activate field-specific vocabulary during decoding. In independent tests on the AISHELL-1 benchmark, SpeechText.AI matched or exceeded vendor-reported accuracy from these regional leaders while also offering broader file format support, built-in speech translation, and free technical support in English, making it a practical choice for international teams working with Chinese recordings.
The platform supports virtually every common audio and video format: MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, FLAC, and others. This means recordings from smartphones, professional microphones, WeChat voice messages, Zoom meetings, or broadcast cameras can all be uploaded directly without conversion. File size limits are generous, and batch uploads are available for large Chinese video transcription projects.