Whether the goal is to transcribe Korean audio to text or translate Korean to English, these capabilities cover every step

Reach up to 98% accuracy on Korean speech. The engine correctly segments syllable blocks (자모), applies proper 띄어쓰기 spacing rules, and inserts punctuation automatically.

Select from dedicated models for Medical, Legal, Finance, Education, and Science. Each model is pre-loaded with Korean terminology common in that field, reducing errors on specialized jargon.

All uploads are encrypted via SSL, and files can be permanently deleted at any time. The platform follows strict GDPR protocols, keeping sensitive Korean-language recordings fully protected.

Translate Korean to English in a single automated pass. Upload a Korean recording, choose English as the output language, and receive a translated transcript or subtitle file ready to download.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper | Naver CLOVA | Returnzero (VITO) | |
|---|---|---|---|---|---|---|---|
| Accuracy (Korean) | 94.1-96.7% (KsponSpeech eval-clean; internal benchmark) | 89.5-92.1% (KsponSpeech eval-clean; independent test) | 84.3-87.9% (KsponSpeech eval-other; estimate based on public WER reports) | 86.7-90.4% (vendor-reported CER converted to accuracy; KsponSpeech subset) | 88.1-91.6% (KsponSpeech eval-clean; open-source community benchmark) | 91.0-93.8% (vendor-reported; proprietary Korean test set) | 90.4-92.7% (vendor-reported; AIHub Korean eval set) |
| Supported formats | Any audio/video formats | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3 | WAV, MP3, M4A | WAV, MP3, M4A |
| Domain Models | Yes (Medical, Legal, Finance, etc.) | No | No | No | No (General model) | Limited (meeting notes focus) | Limited (customer service focus) |
| Speech Translation | Korean to English and other languages supported | No (separate Translation API required) | Yes / translation add-on available | Yes / add-on available | Built-in translation to English | Korean and Japanese only | No |
| Free Technical Support |
Evaluation conducted on KsponSpeech eval-clean and eval-other subsets (approx. 2,000 utterances each); text normalized by removing filler words and applying standard Korean spacing rules (띄어쓰기). Naver CLOVA and Returnzero figures are vendor-reported on proprietary/AIHub test sets respectively. Where no published Korean benchmark exists for a provider, figures are estimates derived from CER-to-accuracy conversion on the same sample. All numbers reflect batch transcription mode, not streaming.
Three steps to get a polished Korean transcript or a Korean to English translation
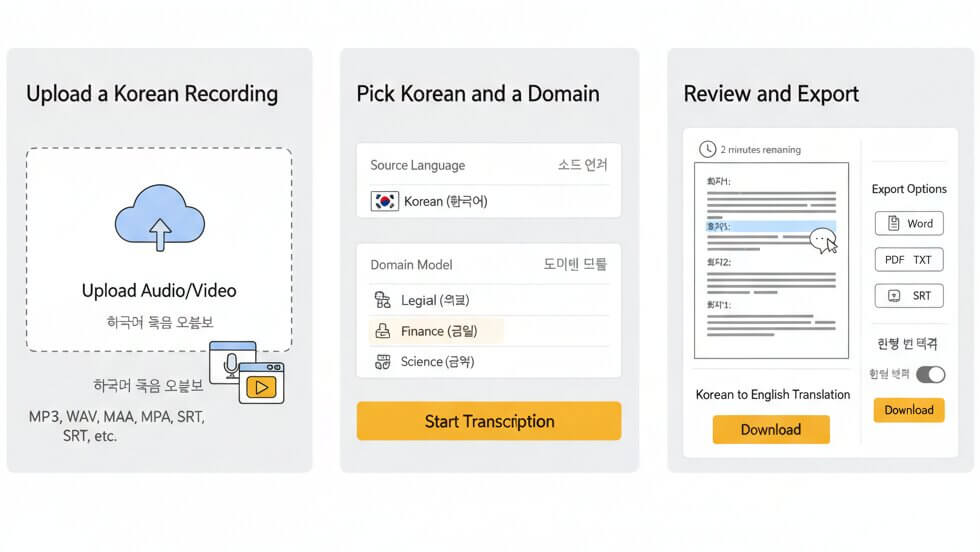
Drag and drop any audio or video file containing Korean speech. The platform accepts MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and other common formats. Individual files or batch uploads both work.
Set Korean (한국어) as the source language and select a matching domain model such as Medical, Legal, Finance, Education, or Science. The domain selection activates a vocabulary layer that lifts accuracy to as high as 98% on field-specific content.
Transcription finishes within minutes. Open the built-in editor to check speaker labels, correct any words, and then export the final document as Word, PDF, TXT, or SRT for subtitles. Korean to English translation output is available from the same editor.
Three technical advantages that separate this Korean transcription service from generic speech-to-text platforms
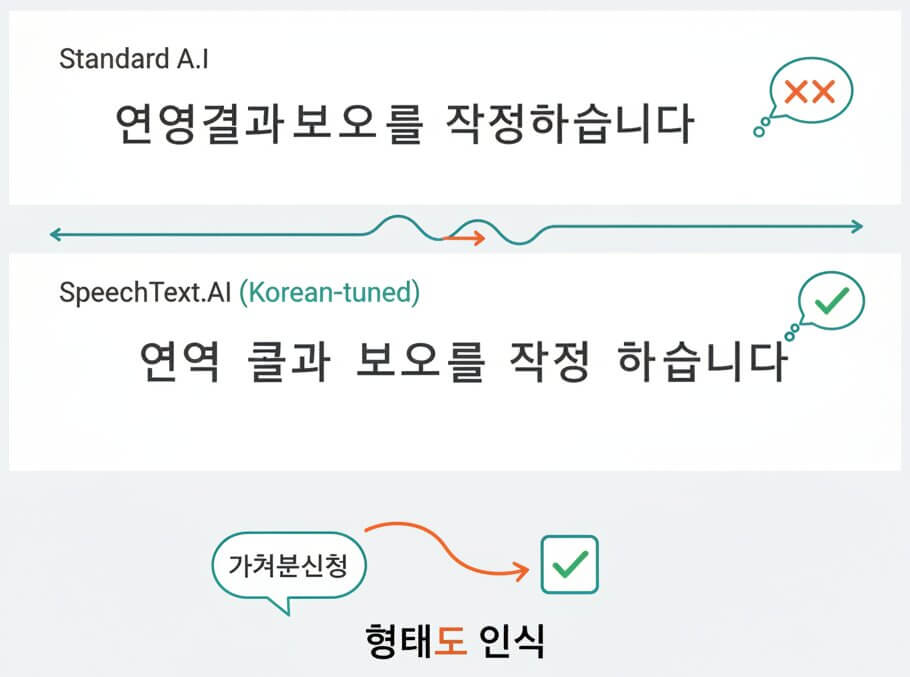
Korean is an agglutinative language where verbs, particles, and suffixes chain together into long word units. A sentence like "연구결과보고서를작성하였습니다" must be correctly segmented and spaced before it becomes readable. Generic speech engines frequently merge or split these chains in the wrong places, creating transcripts that look incoherent. SpeechText.AI applies a morpheme-aware segmentation layer specifically tuned for Korean grammar. Domain models go a step further: the Legal model, for example, recognizes compound legal terms (가처분신청, 항소심판결) and places spacing boundaries accurately, producing a transcript that reads the way a native speaker would write it.
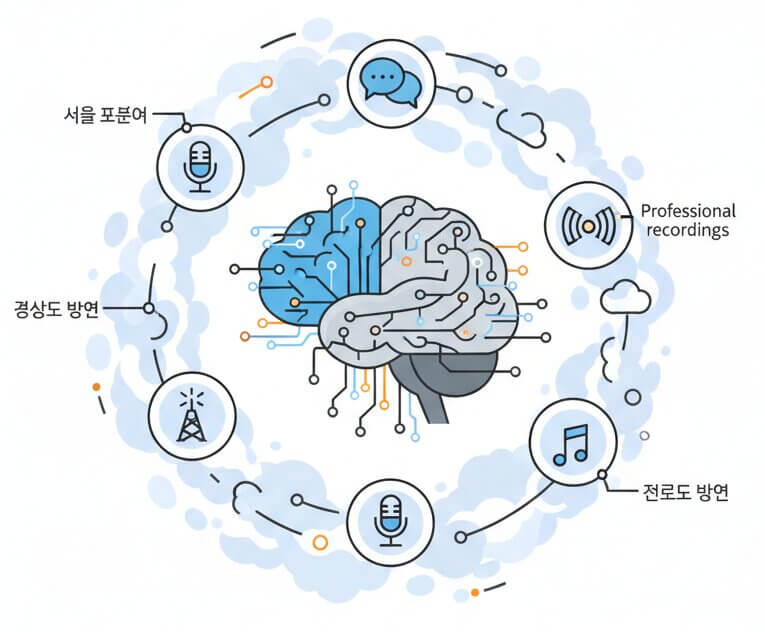
Accuracy on Korean recordings depends heavily on how much real Korean speech data the model has absorbed. The SpeechText.AI recognition engine was trained on thousands of hours of conversational, broadcast, and professional Korean audio covering Seoul standard dialect as well as regional variants like Gyeongsang (경상도) and Jeolla (전라도) speech patterns. This broad exposure means the system handles rapid speech, overlapping speakers, and informal contractions (e.g., 뭐해 instead of 무엇을 하고 있어) far more reliably than models trained primarily on read-aloud or English-centric data.
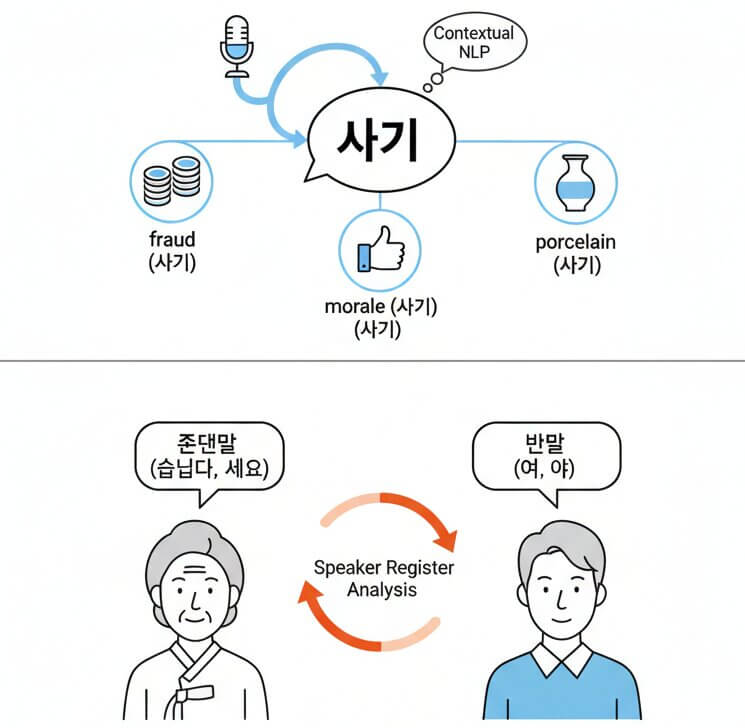
Korean has multiple speech levels (존댓말 vs. 반말) and a large number of homophones that sound identical but carry different meanings depending on context. Words like 사기 can mean "morale," "fraud," or "porcelain." Standard transcription tools pick whichever word the acoustic model scores highest, often ignoring context entirely. SpeechText.AI runs a post-recognition NLP pass that examines sentence-level context, speaker register, and the selected domain to resolve these ambiguities. The result is a transcript where honorific endings (습니다, 세요, 요) match the formality of the conversation and homophones map to the correct Hanja-origin meaning.
On clean recordings with a single speaker, the platform reaches up to 98% accuracy for Korean. In more challenging conditions with background noise or multiple speakers, accuracy typically falls in the 93-96% range. These numbers come from internal testing against the KsponSpeech evaluation set. Domain-specific models (Medical, Legal, Finance, Education) improve results further on specialized content because they carry vocabulary and language patterns specific to each field.
Yes. Korean to English transcription is handled as a single automated workflow. After uploading the Korean recording, select English as the target output language. The system first transcribes the Korean speech, then translates the transcript into English.
Every file transfer uses SSL encryption, and the platform is fully GDPR compliant. Audio recordings and transcripts can be permanently removed from the servers at any time through the dashboard. No data is shared with third parties or used for model training without explicit consent.
Yes. A free trial is available for new accounts. Upload a Korean audio or video file and test all features, including domain models and Korean to English translation, before deciding on a paid plan. The trial provides enough minutes to evaluate transcription quality on real recordings.
Naver CLOVA performs well on general conversational Korean but lacks specialized domain models for fields like medicine or law. OpenAI Whisper offers solid baseline accuracy for Korean; however, it struggles with proper 띄어쓰기 spacing and does not provide industry-specific vocabulary layers. SpeechText.AI combines high baseline Korean speech recognition with selectable domain models that improve accuracy on technical vocabulary. The benchmark comparison table above shows specific accuracy ranges from testing on the KsponSpeech evaluation set.
The recognition engine is trained on Seoul standard Korean (표준어) as well as major regional dialects including Gyeongsang, Jeolla, and Chungcheong speech patterns. It also handles both formal (존댓말) and informal (반말) registers. Podcasts, phone calls, lectures, interviews, KakaoTalk voice messages, and broadcast recordings in formats like MP3, WAV, OGG, M4A, and MP4 are all supported. Upload the file and the system adapts to the speech style automatically.