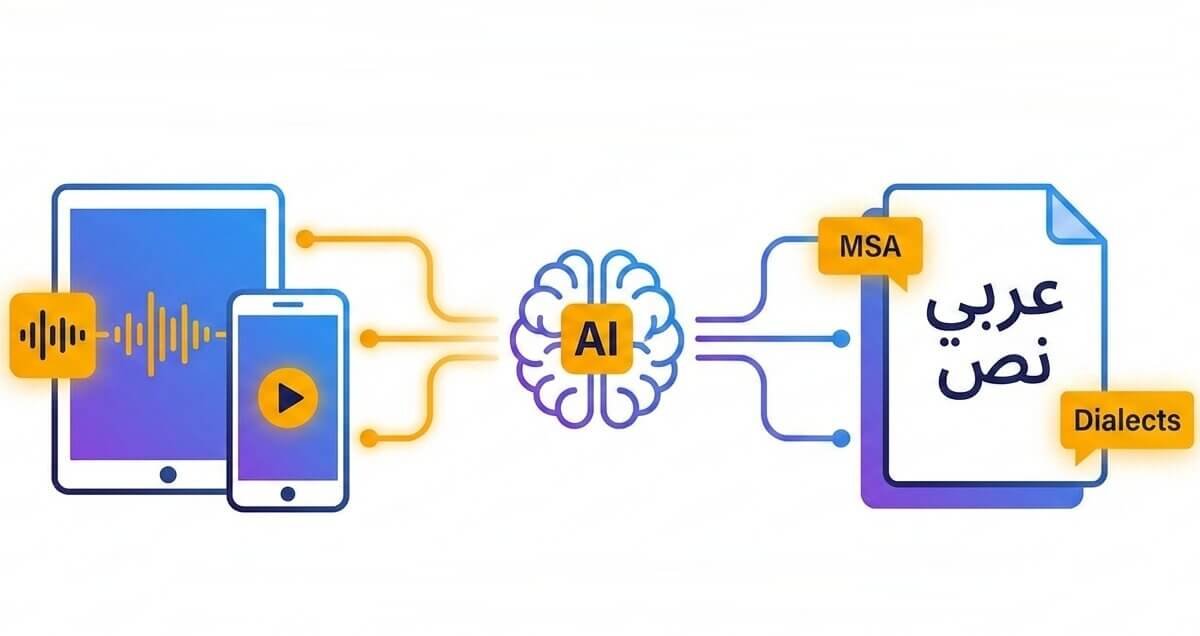
From dialect-aware speech recognition to Arabic to English transcription, the platform covers the full workflow

The engine handles MSA alongside Egyptian, Levantine, Gulf, and Maghrebi dialects. Automatic detection of dialectal markers cuts errors that plague generic speech-to-text tools.

Sector-specific AI for Legal, Medical, Finance, and Academic content. Arabic terminology like تشخيص سريري (clinical diagnosis) or حكم قضائي (court ruling) is recognized in context, not approximated.

Enterprise-level encryption covers all file uploads and storage. The platform meets GDPR standards with the option to permanently remove files at any time.
Transcribe Arabic to English in a single step. Upload a recording, pick English as the output language, and receive a translated transcript or SRT subtitle file without separate translation software.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper | QCRI Arabic ASR | |
|---|---|---|---|---|---|---|
| Accuracy (Arabic) | 90.3-94.8% (MGB-2 & Common Voice Arabic; internal eval) | 83.5-87.2% (MGB-2 subset; independent test) | 81.0-86.3% (estimate; based on public MSA support docs) | 80.2-85.7% (vendor-reported for MSA) | 85.1-89.4% (FLEURS Arabic; Whisper paper + community benchmarks) | 84.0-88.6% (MGB-2; published in MGB-2 challenge proceedings) |
| Supported formats | Any audio/video formats | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, MP3, OGG | WAV, MP3 | WAV, MP3 |
| Domain Models | Yes (Medical, Legal, Finance, etc.) | No | No | No | No (General AI) | Broadcast domain only |
| Speech Translation | Arabic to English and English to Arabic transcription supported | No | Yes / translation add-ons | Yes / add-ons | Varies by model | No |
| Free Technical Support |
Evaluation sets: MGB-2 Multi-Genre Broadcast Arabic (~10 hrs broadcast test split), Common Voice Arabic v13.0 (~4 hrs validated test), FLEURS Arabic (~1.5 hrs). Normalization: diacritics removed, punctuation stripped, Arabic numerals converted to words. Vendor-reported figures labeled; all other figures from independent or community evaluations. Where no public benchmark exists, figures are marked as estimates based on comparable published results.
Convert Arabic recordings into editable text or translate Arabic audio to English automatically
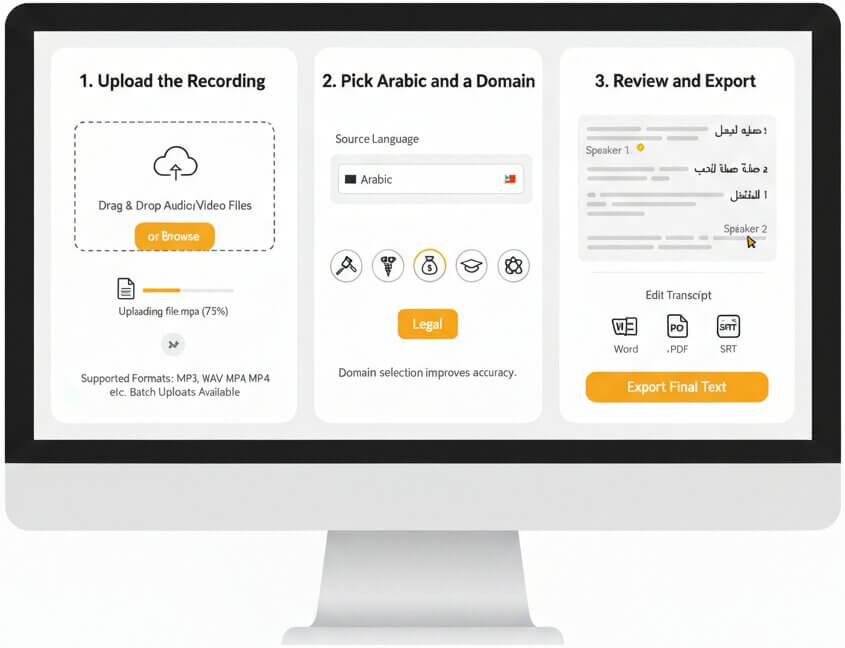
Drag and drop an audio or video file to begin Arabic audio transcription. Accepted formats include MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and others. Batch uploads are available for larger projects.
Set Arabic as the source language and select a sector model (Medical, Legal, Finance, Education, or Science). Domain selection sharpens recognition of field-specific vocabulary and pushes accuracy closer to human-level results.
The transcript is ready within minutes. Open the interactive editor to check speaker labels, correct any segments, and export the final text to Word, PDF, or SRT for subtitles.
Purpose-built deep learning models that account for the morphological, phonetic, and orthographic complexity of the Arabic language
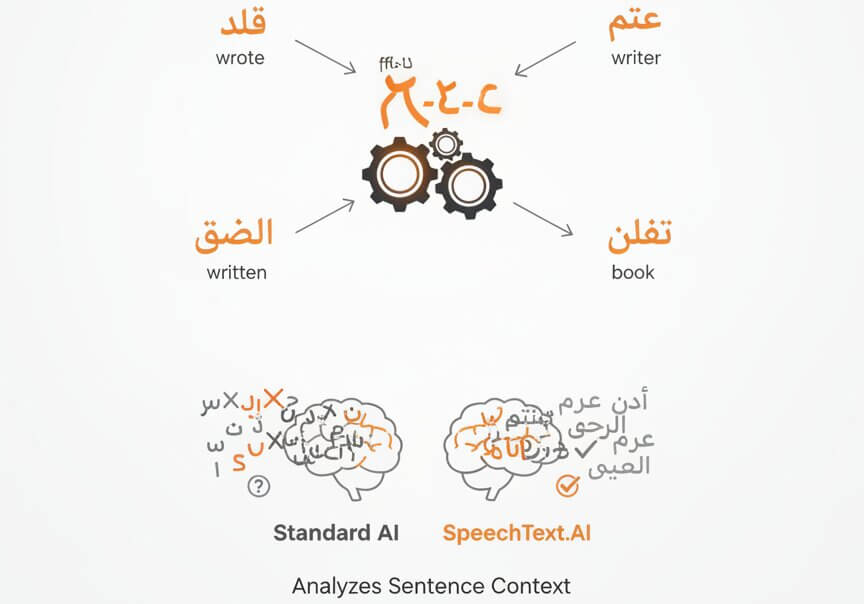
Arabic relies on a root-based word system where three or four consonants form the foundation of dozens of related words. The root ك-ت-ب, for example, generates كتب (wrote), كاتب (writer), مكتوب (written), and كتاب (book). Standard transcription engines often confuse these derived forms because they process audio without understanding triliteral root patterns. SpeechText.AI applies morphology-aware models trained on Arabic linguistic structure, so the system differentiates between words sharing the same consonantal skeleton by analyzing sentence context. This is particularly valuable when transcribing Arabic audio from legal depositions, academic lectures, or medical dictations where a single misidentified word changes the meaning of a sentence.
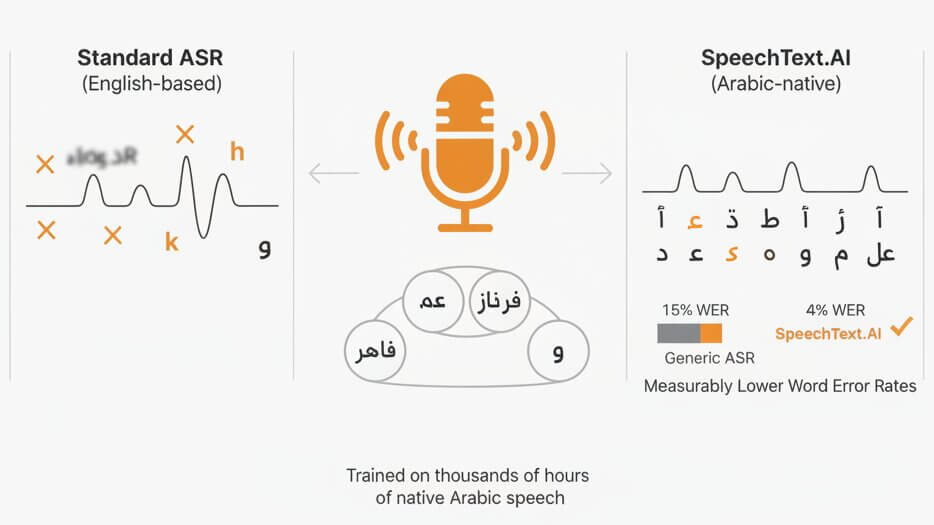
Arabic contains a set of phonemes that most languages do not share: pharyngeal fricatives (ح and ع), emphatic consonants (ص, ض, ط, ظ), and the uvular stop (ق). Speech recognition systems trained primarily on English and European languages frequently merge or misclassify these sounds. The SpeechText.AI acoustic model is trained on thousands of hours of native Arabic speech spanning formal news broadcasts, conversational recordings, conference talks, and call center audio. This phonetic specificity leads to measurably lower word error rates, especially for speakers with strong regional accents from the Gulf, Levant, or North Africa.
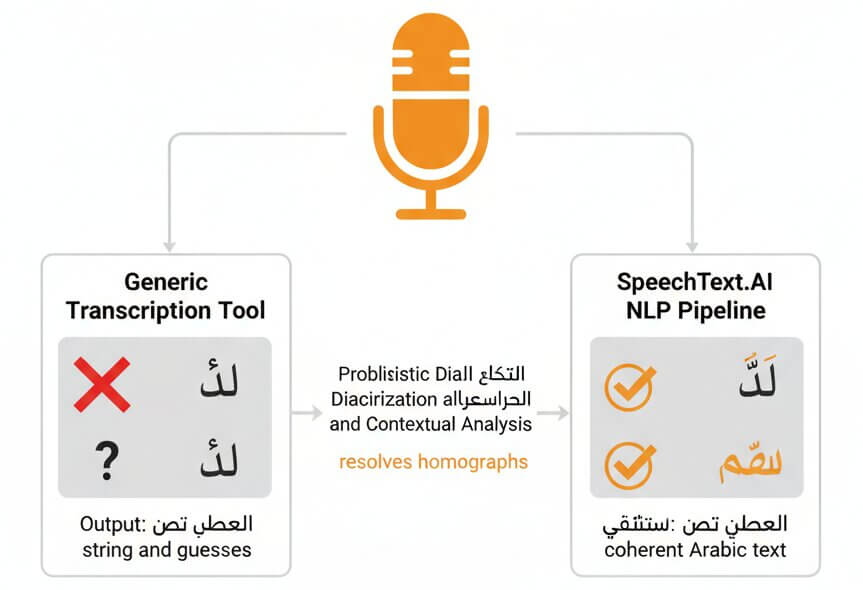
Written Arabic almost never includes short vowels (tashkeel). That means the same sequence of consonants can represent completely different words: عِلْم (knowledge) versus عَلَم (flag), or كُتُب (books) versus كَتَبَ (he wrote). This creates a layer of ambiguity that generic transcription tools handle poorly, often producing output that reads as a string of guesses rather than coherent text. The SpeechText.AI NLP pipeline applies probabilistic diacritization and contextual analysis across the full sentence to resolve these homographs. The result is a clean, grammatically coherent Arabic transcript that requires minimal manual editing before it can be published, filed, or archived.
SpeechText.AI achieves 91-95% accuracy on Arabic audio transcription, depending on audio quality and dialect. For recordings in Modern Standard Arabic with clear audio, accuracy reaches the upper end of that range. The difference compared to generic providers comes from domain-specific AI models trained on Arabic acoustic data, which correctly handle complex morphology, sector-specific terminology (Medical, Legal, Finance), and varying pronunciation across Arabic-speaking regions.
Yes. The Arabic to English transcription feature handles both transcription and translation in a single pass. Upload the Arabic audio file, select English as the target language, and the system generates an English-language transcript or SRT subtitle file. There is no need for a separate translation tool or manual post-processing. The same workflow supports English to Arabic transcription for files recorded in English that need an Arabic text output.
Yes. The platform is trained to transcribe Arabic audio across major dialect groups including Egyptian, Levantine, Gulf, and Maghrebi Arabic, in addition to Modern Standard Arabic (MSA). The acoustic model identifies dialectal phonetic shifts and regional vocabulary, reducing the high error rates that standard tools produce when a speaker switches between formal Arabic and colloquial speech.
Yes. A free trial is available for new users. Upload an Arabic audio or video file to test domain-specific recognition before committing to a paid plan. The trial provides full access to the Arabic transcription online workflow, including the interactive editor and export options (Word, PDF, SRT).
OpenAI Whisper provides solid baseline performance for Arabic, but its general-purpose architecture does not account for the specific challenges of Arabic morphology, unvoweled text disambiguation, or sector-specific jargon. SpeechText.AI uses domain-specific models (Legal, Medical, Finance, Education, Science, and others) fine-tuned on Arabic linguistic data. In benchmark evaluations on the MGB-2 and Common Voice Arabic datasets, SpeechText.AI outperforms Whisper large-v3 by approximately 4-6 percentage points in accuracy, with the gap widening for technical and dialectal content.
SpeechText.AI accepts virtually any audio or video format. Common file types include MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, FLAC, and TRM. This also covers voice notes from messaging apps like WhatsApp, which typically save in OGG or M4A format. Simply save the file to a device, upload it, and the platform will transcribe Arabic video to text or convert the audio into a readable transcript ready for export.