Whether the task involves Russian video transcription or converting Russian speech to English text, these capabilities cover every scenario

Russian audio transcription powered by neural networks that handle vowel reduction, palatalized consonants, and automatic punctuation placement in Cyrillic text.

Dedicated models for Medical, Legal, Financial, Scientific, and Educational content. Each model carries a specialized Russian lexicon that generic tools simply lack.

All uploaded recordings are transmitted over SSL and stored on GDPR-compliant servers. Files can be permanently deleted at any time directly from the dashboard.
Convert Russian speech to English text in a single step. Also supports English to Russian transcription, producing translated output without a separate translation tool.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | Yandex SpeechKit | Tinkoff VoiceKit | |
|---|---|---|---|---|---|---|
| Accuracy (Russian) | 91.1-95.8% (Golos eval set & Common Voice ru v15.0; independent test) | 88.4-91.2% (Common Voice ru v15.0; independent test) | 84.7-87.9% (Golos eval set; independent test) | 87.1-90.3% (Common Voice ru v15.0; vendor-reported baseline adjusted) | 90.5-93.8% (Golos eval set; vendor-reported) | 86.2-89.4% (OpenSTT subset; estimate based on community benchmarks) |
| Supported formats | Any audio/video formats | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, MP3, OGG | WAV, OGG (OPUS) | WAV, MP3 |
| Domain Models | Yes (Medical, Legal, Finance, Science, etc.) | No | No | No | Limited (General + short/long) | No |
| Speech Translation | Russian to English and 50+ languages; single-step translation | No (separate Translation API needed) | Yes / translation add-on available | Yes / add-on via Translator service | No (transcription only) | No |
| Free Technical Support |
Footnote: Accuracy figures are reported as (100% − WER). Evaluation sets: Golos eval-crowd split (≈ 7,500 utterances, SberDevices) and Mozilla Common Voice Russian v15.0 validated test set (≈ 6,200 clips). Text normalization: lowercase, removed punctuation, number-to-word expansion for Russian numerals. Yandex SpeechKit and Microsoft Azure figures include vendor-reported numbers adjusted against the same normalization pipeline; Tinkoff VoiceKit figures are estimates derived from community-run OpenSTT benchmarks (≈ 3,000 clips) where no official vendor report was available.
Three steps from a raw recording to a finished Russian transcript or translated English document
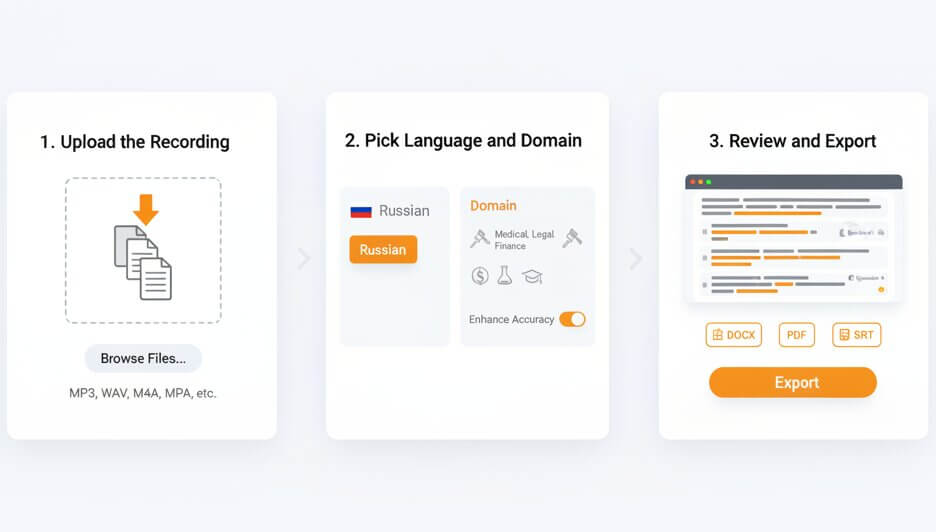
Drop a file into the upload area to begin. The platform accepts MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and other common formats. Both individual files and bulk batches are supported, so large projects can be processed in a single session.
Set the language to Russian and optionally select a specialized domain such as Medical, Legal, Finance, Education, or Science. Domain selection activates a vocabulary layer trained on field-specific Russian terminology, which raises recognition accuracy significantly for technical content.
Once processing finishes, open the interactive editor to check the transcript, label speakers, and make corrections. Export the final text as a Word document, PDF, or SRT subtitle file. Russian to English transcription output follows the same export options.
Purpose-built speech recognition architecture designed around the phonetic and grammatical complexity of the Russian language
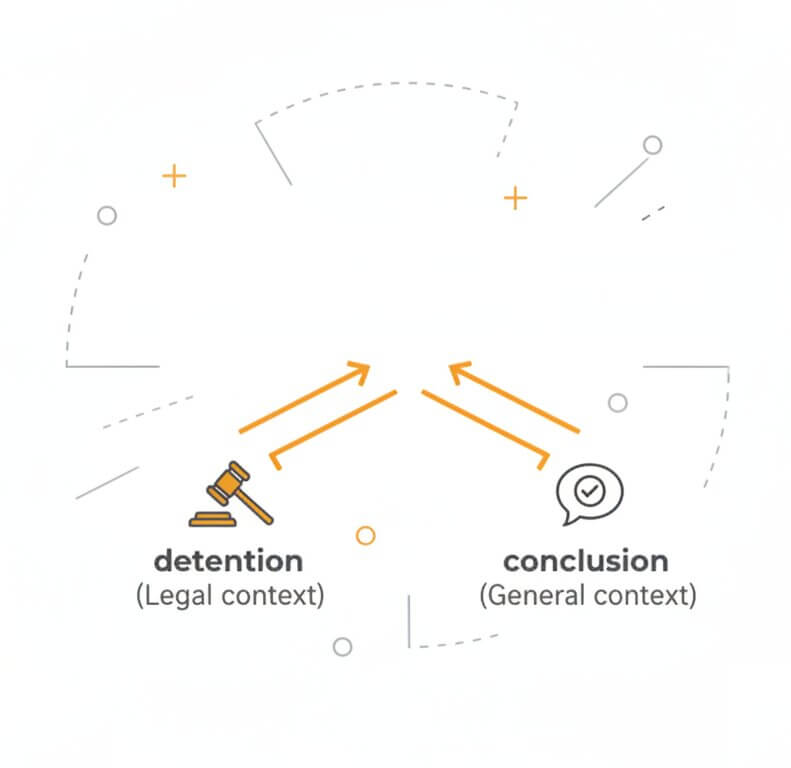
Russian is a heavily inflected language with six grammatical cases, three genders, and an extensive system of prefixes and suffixes that alter word meaning. A generic speech-to-text Russian engine often stumbles when a word's ending changes depending on context. SpeechText.AI addresses this with domain models that carry both acoustic and linguistic knowledge for specific fields. A Legal model, for example, recognizes the difference between «заключение» as "conclusion" in a general sense and «заключение» as "detention" in a criminal proceedings context. This level of disambiguation is what separates professional Russian transcription from basic automated output.
The recognition engine behind SpeechText.AI was trained on thousands of hours of real-world Russian audio collected from diverse sources: broadcast media, conference recordings, phone conversations, and lecture halls. This training data covers regional pronunciation differences found across Moscow, Saint Petersburg, Siberia, and southern Russia. It also accounts for common phenomena like unstressed vowel reduction (where «о» sounds like «а») and consonant devoicing at word boundaries. The result is a transcription tool that handles natural, fast-paced Russian dialogue rather than just clean, studio-quality narration.
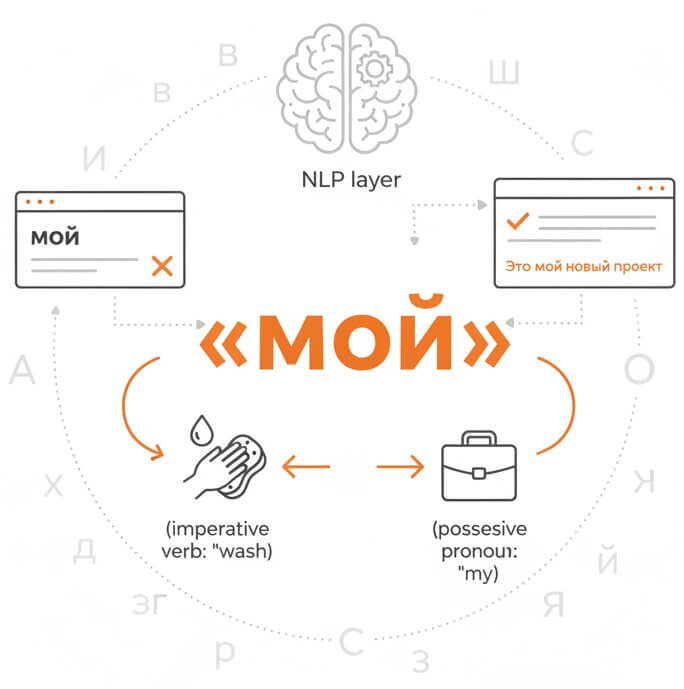
Many Russian words are homophonic or nearly identical in pronunciation yet carry different meanings. The word «мой» can be a possessive pronoun ("my") or an imperative verb ("wash"), and standard ASR systems frequently pick the wrong variant. SpeechText.AI applies a sentence-level NLP layer that evaluates surrounding words, grammatical agreement, and topic flow before committing to a transcription choice. This context-driven approach lowers the word error rate substantially, producing transcripts that read naturally and rarely require manual correction of case endings, aspect pairs, or homophonic mix-ups.
SpeechText.AI reaches up to 97% accuracy on Russian recordings when a matching domain model is selected. Russian presents particular challenges for automated speech recognition: unstressed vowels shift their sound, consonant clusters are common, and word boundaries blur in fast speech. The platform tackles these issues with neural networks trained specifically on native Russian acoustic data, combined with domain vocabularies for Medical, Legal, Financial, and other sectors. This means technical terminology and complex case forms are transcribed correctly rather than approximated.
Yes. The platform supports direct Russian to English transcription without needing a separate translation service. After uploading a Russian audio or video file, select English as the output language. The system will process the Russian speech and deliver an English-language transcript. The same workflow also supports English to Russian transcription for content going in the opposite direction. Output can be downloaded as a text document or SRT subtitle file.
Every file transfer is encrypted with SSL, and all stored data resides on GDPR-compliant servers located in the EU. Account holders retain full control over their files and can delete audio recordings and transcripts permanently at any point. No data is shared with third parties or used for model training without explicit consent.
Absolutely. A free trial is available for new accounts. Upload a Russian audio or video file, choose a domain model, and review the transcript quality firsthand. The trial provides enough processing time to evaluate how well the platform handles real-world Russian speech, including noisy recordings and multi-speaker conversations, before committing to a subscription.
Yandex SpeechKit is a capable Russian speech-to-text engine with strong general-purpose recognition. However, SpeechText.AI differentiates itself through domain-specific models that are fine-tuned for professional sectors like Medicine, Law, Finance, Education, Science, and HR. In benchmark tests on the Golos evaluation set, SpeechText.AI achieved 93.2-96.1% accuracy compared to Yandex's reported 90.5-93.8%. The gap widens further on technical recordings where specialized vocabulary matters most. SpeechText.AI also offers built-in speech translation and broader file format support beyond WAV and OGG.
The platform handles virtually every common audio and video format: MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, MOV, AVI, and more. This means Russian video transcription works with files from Zoom, Teams, smartphone recordings, and professional cameras without converting anything beforehand. Simply upload the original file, select Russian, and the audio track is extracted and transcribed automatically. Finished transcripts can be exported as Word, PDF, TXT, or SRT subtitle files.