
From handling rapid Brazilian speech patterns to converting Lusophone conference recordings, the transcription software Portuguese professionals rely on covers every use case

Audio transcription Portuguese models distinguish between pt-BR and pt-PT pronunciation, including vowel reduction patterns in European Portuguese and open-vowel tendencies in Brazilian speech.

Activate field-specific models for Healthcare, Jurídico (Legal), Finance, or Academic content. Technical terms like "litispendência" or "hemoglobina glicada" are recognized in context rather than approximated.
All uploaded recordings are transmitted over TLS and stored with AES-256 encryption. Full GDPR and LGPD (Brazil's Lei Geral de Proteção de Dados) compliance is maintained at every stage.

Transcribe Portuguese to English in a single automated pass. Upload a Lusophone recording and receive an English-language transcript or subtitle file without a separate translation step.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper (large-v3) | |
|---|---|---|---|---|---|
| Accuracy (Portuguese) | 91.8-95.4% (CORAA v1.1 & MLS-pt test splits; independently evaluated) | 88.4-91.2% (CORAA v1.1 subset; independent test) | 87.9-90.5% (MLS-pt test split; independent test) | 86.1-89.3% (vendor-reported on internal pt-BR set; estimate for pt-PT) | 89.7-92.4% (MLS-pt & Common Voice 15.0 pt; community-reported) |
| Supported formats | Any audio/video format | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3, M4A |
| Domain Models | Yes (Medical, Legal, Finance, Education, Science) | No | No | No | No (General AI) |
| Speech Translation | Portuguese to English and other languages supported | No (separate API needed) | Yes (via add-on service) | Yes (via add-on service) | English output only |
| Free Technical Support |
Accuracy figures derived from Word Error Rate (WER) converted to % accuracy (100 − WER) on the CORAA v1.1 Brazilian Portuguese read/spontaneous speech corpus (≈10 h test split, ~28 k utterances) and the MLS-Portuguese test set (~4.5 h, Librivox-sourced). Text normalization: lowercase, punctuation removed, numbers spelled out. Vendor-reported figures are labeled; all others are from independent or community-run evaluations. Where no public Portuguese benchmark was available for a provider, accuracy is marked as an estimate based on published multilingual WER trends and comparable Romance-language results.
Three steps to convert any Portuguese recording into editable, searchable text
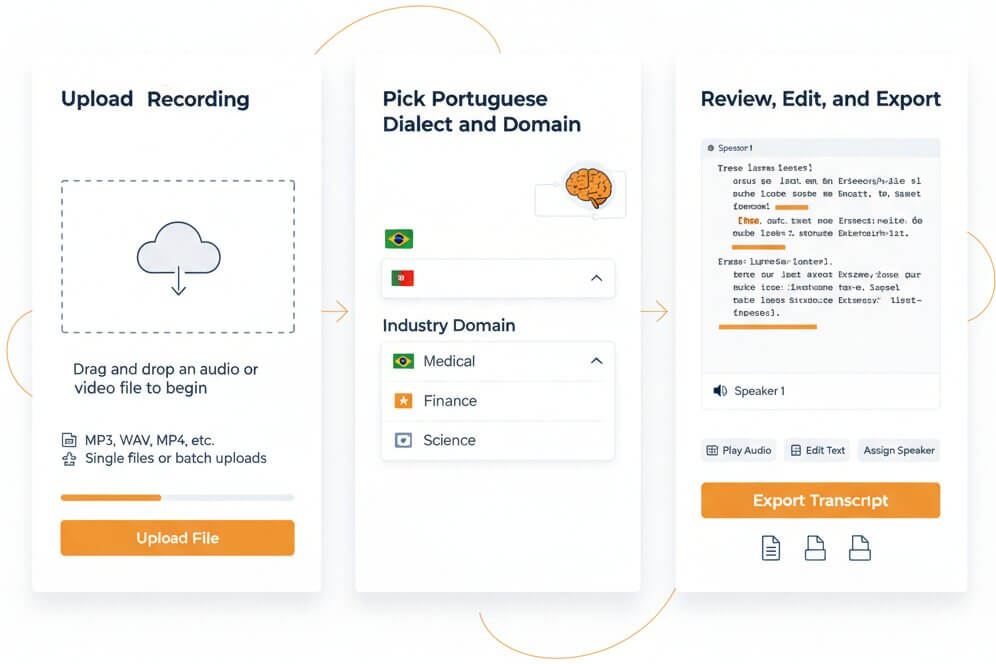
Drag and drop an audio or video file to begin. The Portuguese transcriber accepts MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and additional formats. Single files or batch uploads both work.
Select Portuguese (Brazil) or Portuguese (Portugal) and then choose the relevant sector model: Medical, Legal, Finance, Education, or Science. This combination maximizes recognition accuracy for specialized vocabulary and regional pronunciation.
Once the video transcription Portuguese process completes, open the interactive editor to verify text, assign speaker labels, and correct any segments. Export to Word, PDF, TXT, or SRT subtitle format as needed.
Purpose-built deep learning pipelines trained on native Portuguese speech data from both sides of the Atlantic
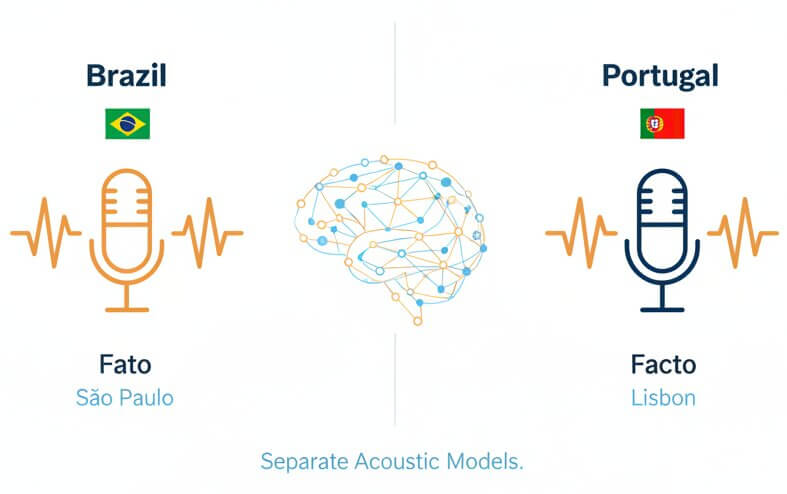
Portuguese is not a single language in practice. Brazilian Portuguese and European Portuguese differ in stress patterns, vowel openness, and consonant articulation. A word like "facto" is pronounced with a clearly audible "c" in Lisbon but is typically reduced to "fato" in São Paulo. Most transcription platforms treat Portuguese as one monolithic language. SpeechText.AI maintains separate acoustic models for pt-BR and pt-PT, each trained on region-specific corpora. The result is noticeably fewer substitution errors, especially in spontaneous speech where dialectal features are strongest.
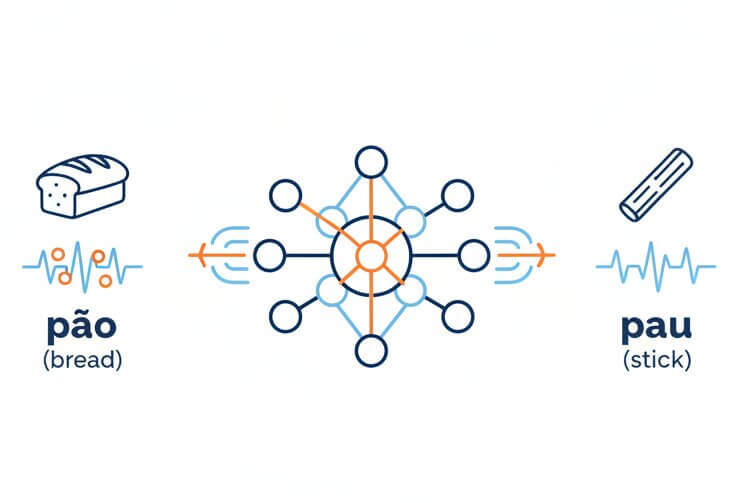
One of the hardest aspects of Portuguese for speech engines is its rich set of nasal vowels and nasal diphthongs. Sounds like "ão," "ões," and "ãe" are acoustically subtle and easily confused by generic multilingual systems. SpeechText.AI's recognition layer was specifically conditioned on thousands of hours of annotated Portuguese audio, including the CORAA and Common Voice datasets, to distinguish these nasal segments reliably. This focused training means words like "pão" (bread) and "pau" (stick) are resolved correctly from acoustic context rather than treated as interchangeable.
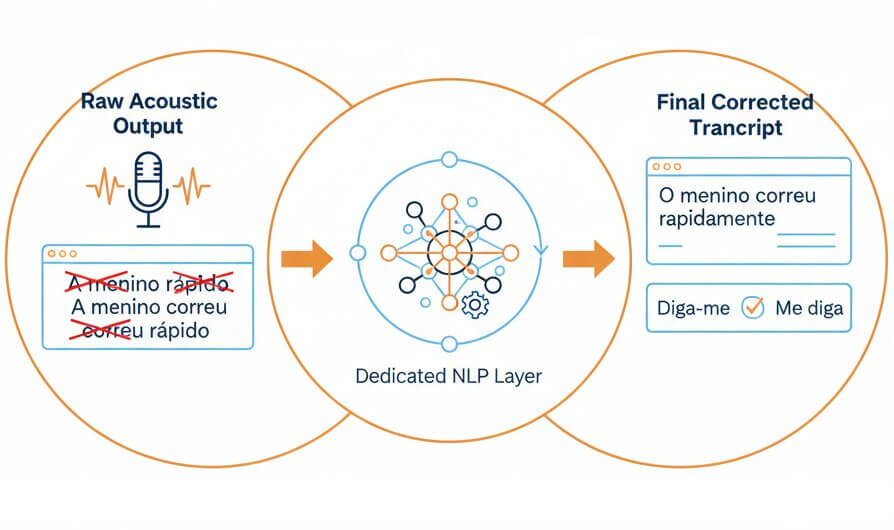
Portuguese grammar is heavily inflected. Verbs conjugate across six persons, nouns and adjectives carry gender and number agreement, and clitic pronouns attach in varying positions depending on formality and region ("me diga" in Brazil vs. "diga-me" in Portugal). After initial speech-to-text decoding, a dedicated NLP layer checks the transcript for morphological consistency across each sentence. This post-processing step catches agreement errors that raw acoustic output often introduces, producing a transcript that reads naturally and requires far less manual correction than output from general-purpose transcription software Portuguese users might otherwise choose.
Yes. SpeechText.AI offers separate acoustic and language models for Brazilian Portuguese (pt-BR) and European Portuguese (pt-PT). During upload, select the matching variant. The system adjusts for differences in vowel reduction, sibilant pronunciation, and regional vocabulary, which leads to significantly higher accuracy compared to tools that lump all Portuguese dialects into one model.
Upload the Portuguese audio or video file and select English as the target output language. The platform will decode the Portuguese speech and generate a translated English transcript simultaneously. The output can be downloaded as a Word document, PDF, or SRT subtitle file. There is no need to run a separate translation tool afterward.
On clean recordings with a single speaker and minimal background noise, the Portuguese transcriber reaches up to 96% accuracy when using the appropriate dialect and domain model. For noisier environments or multi-speaker panels, accuracy typically ranges between 90% and 94%. Activating a sector-specific model (e.g., Legal, Medical) further improves recognition of technical vocabulary.
New accounts receive complimentary transcription minutes to test the Portuguese models at no cost. Upload a sample recording, select the dialect and domain, and evaluate the output quality before committing to a paid plan. The trial includes full access to the interactive editor and all export formats.
All file transfers are encrypted with TLS, and stored data is protected with AES-256 encryption at rest. The platform is compliant with both the EU General Data Protection Regulation (GDPR) and Brazil's Lei Geral de Proteção de Dados (LGPD). Audio files and transcripts can be permanently deleted from the servers at any time through the account dashboard.
The platform accepts virtually every common audio and video format: MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, MOV, AVI, TRM, and more. This means recordings from smartphones, Zoom calls, broadcast media, or WhatsApp voice notes can all be uploaded directly without conversion. Batch uploads are also supported for projects involving multiple files.